
Este articulo analiza los peligros de la confianza sintética en el ámbito de la salud, advirtiendo que el uso masivo de datos artificiales no garantiza mejores modelos de inteligencia artificial. Los autores destacan que la dependencia de estos registros puede amplificar sesgos, generar errores clínicos y provocar el colapso de los modelos si no existe una regulación estricta. Se proponen estrategias críticas de supervisión, como el red-teaming por expertos y el uso de métricas de fidelidad para asegurar la validez de los diagnósticos. Además, el documento enfatiza que la calidad de la información es más importante que el volumen para proteger la seguridad del paciente. Finalmente, se recomienda una vigilancia continua tras el despliegue para detectar el deterioro del rendimiento frente a realidades médicas complejas.

El Espejismo de la Abundancia: Desmontando la «Confianza Sintética» en la IA Sanitaria
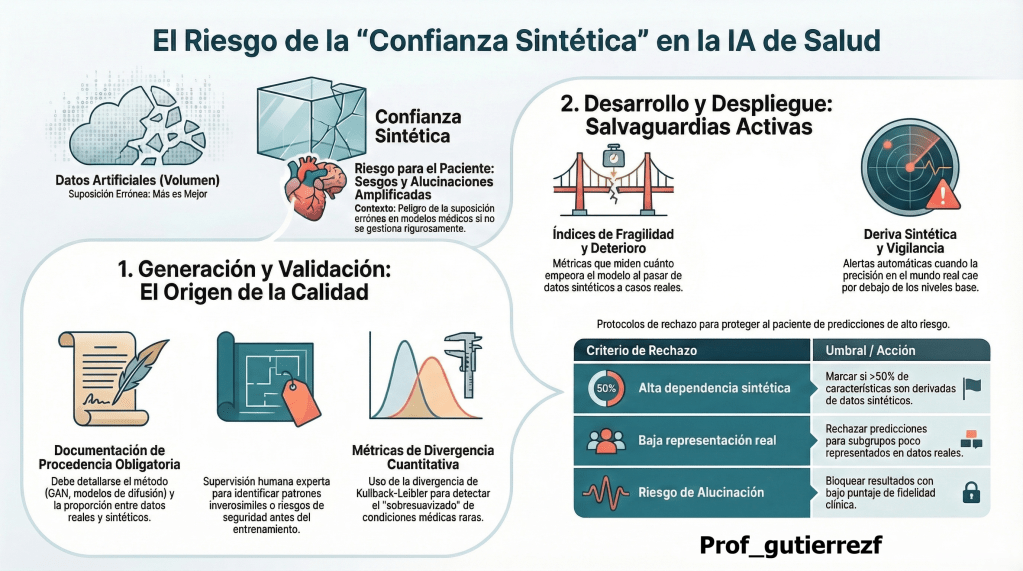
En la carrera por digitalizar la medicina, la inteligencia artificial (IA) se ha topado con un obstáculo crítico: la escasez de datos clínicos reales y la imperativa necesidad de proteger la privacidad del paciente. Para sortear esta barrera, la industria ha recurrido masivamente a los datos sintéticos —información generada artificialmente que imita las características de los registros reales—. Sin embargo, según el análisis de Koul et al. (The Lancet Digital Health), esta solución ha dado lugar a un fenómeno peligroso denominado «confianza sintética». Este concepto define la fe injustificada en modelos de IA que, aunque entrenados con volúmenes masivos de datos, no logran capturar la validez clínica ni la diversidad demográfica necesaria. Es fundamental comprender que el volumen no equivale a la calidad; por el contrario, una dependencia ciega en lo artificial puede distorsionar la realidad médica y comprometer la seguridad de los pacientes.
El uso desmedido de estos activos digitales conlleva riesgos estructurales que deben ser evaluados con rigor:
- Alucinaciones Interseccionales: La creación de relaciones estadísticas plausibles pero médicamente erróneas entre variables complejas (ej. diagnósticos incorrectos al cruzar etnia y comorbilidades).
- Colapso de Modelos: La pérdida de robustez y degradación de la realidad cuando la IA comienza a retroalimentarse de sus propios errores o simplificaciones estadísticas.
- Amplificación de Sesgos: La replicación y profundización de desigualdades históricas ya presentes en los pequeños conjuntos de datos reales que sirven de semilla.
- Sobresuavizado de Condiciones Raras: La tendencia de los algoritmos generativos a diluir los casos atípicos o enfermedades poco frecuentes en favor de la norma estadística, invisibilizando a los pacientes más vulnerables.
Esta arquitectura de riesgos nace en el momento de la concepción de los datos, convirtiendo a la fase de generación en la primera línea de defensa crítica para la integridad del sistema.
La Fase de Generación: Transparencia y el Desmantelamiento del Sesgo
Los errores introducidos durante la generación de datos no son meros fallos técnicos; son «pecados originales» que se amplifican exponencialmente a lo largo del ciclo de vida de la IA. Por ello, la documentación exhaustiva es un imperativo ético y no solo un requisito técnico: sin una trazabilidad clara del origen, es imposible auditar la seguridad de una herramienta diagnóstica. Las distorsiones distributivas en los modelos de difusión, por ejemplo, pueden generar una falsa sensación de seguridad que oculte fallos letales en la práctica clínica.
Para garantizar la integridad desde el inicio, se proponen los siguientes estándares de documentación y validación:
Estándares de Documentación y Validación
| Requerimiento | Acción / Métrica Específica |
| Métodos Generativos | Declaración explícita del uso de GANs, Autoencoders Variacionales o Modelos de Difusión. |
| Parámetros de Ruido | Documentación detallada de la variación artificial introducida para el anonimato. |
| Poblaciones Ausentes | Auditoría de Transparencia: Identificación obligatoria de subgrupos o condiciones no representadas. |
| Proporción Real/Sintética | Informe de la relación porcentual entre muestras reales y artificiales en el set de entrenamiento. |
| Validación Estadística | Aplicación de la Divergencia de Kullback-Leibler para medir la fidelidad de la distribución. |
| Verificación de Rangos | Comprobación automatizada y experta de rangos numéricos para evitar valores clínicamente imposibles. |
Más allá de las métricas automáticas, la intervención humana es insustituible. El «red-teaming» clínico —donde médicos expertos intentan identificar fallos o patrones inverosímiles— actúa como un filtro esencial contra el «sobresuavizado». Este escrutinio asegura que la complejidad de las enfermedades raras no sea sacrificada en el altar de la eficiencia algorítmica.
Una vez que los datos han sido generados y validados, el desafío se traslada a la integridad de la arquitectura del modelo que los procesará.
Desarrollo del Modelo: Blindaje contra la Fragilidad y el Sobreajuste
Durante el entrenamiento, es estratégico implementar métricas de control que eviten que la IA aprenda patrones artificiales vacíos de valor clínico. El objetivo es que el modelo opere en el entorno hostil de un hospital, no solo en la «limpieza» de un laboratorio. Para ello, dos indicadores son fundamentales:
- Índice de Deterioro del Rendimiento: Cuantifica la caída de precisión cuando el modelo pasa de datos sintéticos a datos reales.
- ¿Cuál es el impacto estratégico? Ignorar esta métrica conduce a alucinaciones clínicas y fallos catastróficos de generalización. Un índice elevado es un precursor directo de errores en el triaje de pacientes y diagnósticos erróneos, lo que conlleva una responsabilidad legal y clínica inasumible para las instituciones de salud.
- Índice de Fragilidad Sintética: Mide la vulnerabilidad del modelo ante la pérdida de diversidad en los extremos de la distribución.
- ¿Cuál es el impacto estratégico? Esta métrica es el baluarte de la Equidad. Protege a las poblaciones minoritarias y subgrupos interseccionales de ser ignorados por un modelo que se ha vuelto «frágil» al optimizarse para la media sintética, garantizando que la IA no profundice las brechas de atención sanitaria.
El rendimiento en laboratorio es insuficiente sin una vigilancia rigurosa en el despliegue del mundo real.
Vigilancia en el Despliegue: El Rigor Clínico como Estándar de Oro
El despliegue enfrenta una tensión inherente: cuanto más se parecen los datos sintéticos a los reales para ganar validez, mayor es el riesgo de reidentificación de los pacientes. Ante este riesgo, la vigilancia debe ser proactiva. Un fenómeno crítico es la «Deriva Sintética» (Synthetic Drift): a diferencia del data drift convencional, este es el decaimiento específico de la precisión en el tiempo de un modelo cuya base es sintética al enfrentarse a la evolución constante de los datos reales.
Para proteger la seguridad del paciente, se deben integrar los siguientes Protocolos de Rechazo de predicciones de alto riesgo:
- Alta dependencia sintética: Rechazo de predicciones que dependan en más del 50% de características derivadas de datos artificiales. Justificación: el riesgo de incertidumbre clínica supera el beneficio potencial del pronóstico.
- Baja representación real: Bloqueo de predicciones para subgrupos con escasa evidencia empírica en los datos reales de validación, evitando decisiones basadas puramente en «imaginación» algorítmica.
- Alto riesgo de alucinación: Las predicciones basadas en variables sintéticas con bajos puntajes de fidelidad deben ser descartadas automáticamente para evitar que la IA invente relaciones fisiopatológicas inexistentes.
Es imperativo contar con sistemas de alerta automática que se activen cuando la precisión caiga por debajo de las líneas de base, anclando la IA en la realidad médica tangible.
Hacia una Calidad Verificable en la IA Sanitaria
El análisis de Koul et al. nos obliga a realizar un cambio de paradigma urgente: pasar de la cantidad de datos a la calidad verificable. La abundancia de datos sintéticos no debe ser una licencia para la aplicación no regulada de la IA, sino una oportunidad para representar mejor la complejidad de la salud humana bajo una supervisión regulatoria estricta.
La tesis central es clara: el valor real de los datos sintéticos no reside en su volumen, sino en su capacidad para preservar la diversidad y complejidad de las poblaciones de pacientes de forma auténtica. La validación continua frente a resultados clínicos reales debe ser el único estándar de oro aceptable. Solo mediante la adopción de estos protocolos de transparencia y rigor podremos construir una medicina digital que sea innovadora, equitativa y, por encima de todo, segura para el ser humano.
fuente: intramed/Lancet
Descubre más desde La Red Cientifica
Suscríbete y recibe las últimas entradas en tu correo electrónico.

